什么是前馈神经网络
前馈神经网络(FFN),神经网络中最简单基础的一种
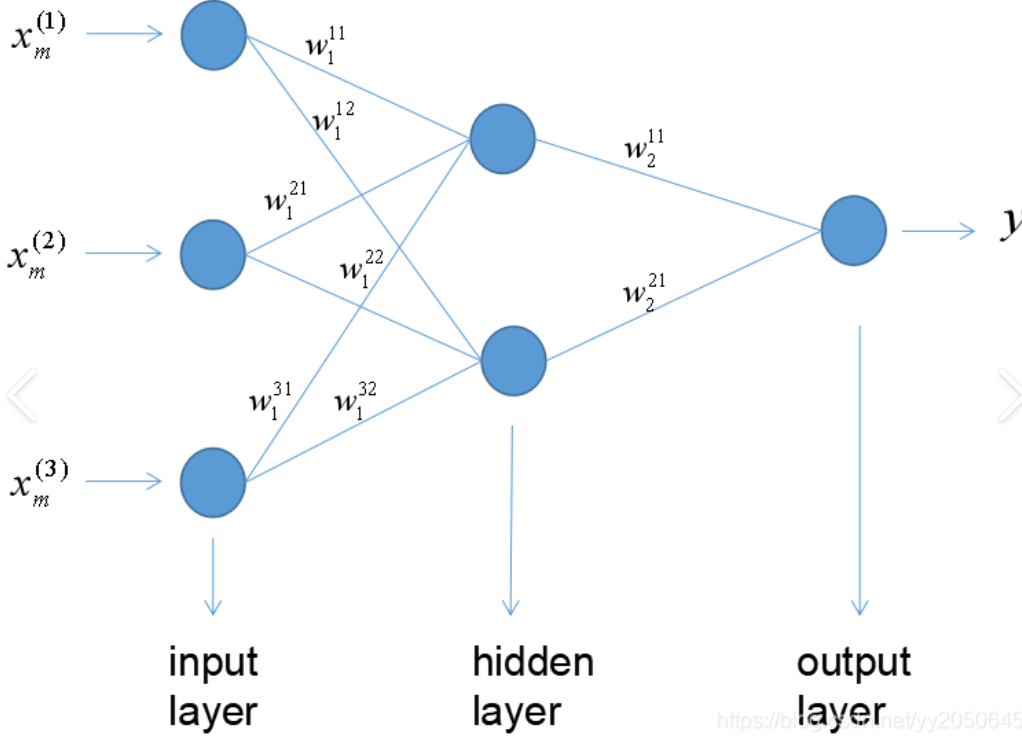
信息只向前流动,经过输入层,隐藏层,输出层。没有任何反馈回路,是最基础的神经网络。
它的每一层只做一件事,输入,线性变换(加权求和),非线性激活,输出给下一层。
线性组合: z = w₁x₁ + w₂x₂ + w₃x₃ + b
非线性激活: a = σ(z) (σ是[[激活函数]],如ReLU、Sigmoid)
为什么这么简单可以完成复杂任务?
因为很多个神经元堆叠后,第一层网络识别颜色边缘,第二层识别形状纹理,第三层识别物体部件,等等。靠着层数的叠加来完成复杂识别。
它有哪些缺陷
| 问题 |
说明 |
解决方案 |
| 全连接参数爆炸 |
输入1000维,隐藏层1000,就有1M参数 |
CNN/局部连接 |
| 无法处理序列 |
输入长度必须固定 |
RNN/Transformer |
| 梯度消失/爆炸 |
深层网络难训练 |
残差连接 + LayerNorm |
| 过拟合 |
参数多,容易记住数据 |
Dropout + 正则化 |
| 忽略空间结构 |
把图像展平会丢失邻域关系 |
CNN |
虽然有着缺陷,但它仍旧很重要
前馈神经网络加上卷积是CNN,加上循环是RNN,加自注意力机制是Transformer
FNN的纬度问题(初始化部分怎么写)
公式:Z = X @ W + b
实现矩阵乘法,X @ W 要能相乘,X的最后一维必须等于W的第一维。
| 符号 |
含义 |
形状 |
X |
输入 |
[batch, 输入维度] |
W |
权重 |
[输入维度, 输出维度] |
b |
偏置 |
[1, 输出维度] 或 [输出维度] |
Z |
输出 |
[batch, 输出维度] |
| 假设现在三个神经元(输出三个值),输入纬度784 |
|
|
1
2
3
4
5
6
7
8
9
10
| import numpy as np
batch = 5
X = np.random.randn(5, 784)
W = np.random.randn(784, 3)
b = np.random.randn(3)
Z = X @ W + b
|
给你一个3层网络:
- 输入层:784维
- 隐藏层1:128个神经元
- 隐藏层2:64个神经元
- 输出层:10个神经元
1
2
3
4
5
6
7
8
| W1.shape = [784, 128] # 输入 → 隐藏层1
b1.shape = [128] 或 (1, 128)
W2.shape = [128, 64] # 隐藏层1 → 隐藏层2
b2.shape = [64] 或 (1, 64)
W3.shape = [64, 10] # 隐藏层2 → 输出层
b3.shape = [10] 或 (1, 10)
|
前向传播
1
2
3
| X → Z1 → A1 → Z2 → A2 → Z3 → A3 (输出)
↓ ↓ ↓
ReLU ReLU Softmax
|
除了最后一层输出层,都是线性变换然后激活,由于我要写的是分类任务所以需要softmax把数值转为概率分布
前向传播的softmax怎么写

代码是这样的
1
2
| exp_z3 = np.exp(z3 - np.max(z3, axis=1, keepdims=True))
a3 = exp_z3 / np.sum(exp_z3, axis=1, keepdims=True)
|
为什么要减去一个最大值呢(z3-np.max)
因为直接e^z3 可能会溢出,然后分子分母同除不会改变大小(在e的指数上操作的所以是减)
axis=1沿着列的方向走,在每一行也就是每个样本里操作。
keepdims=true是因为需要保持维度,作减法时需要维度对齐

softmax之后,可以通过a3得出[[损失函数]]
损失: L = CrossEntropy(y_true, A₃) (一个数字)
怎么直观理解呢,y_true表示实际类别(标签)
1
| y_true = [0,0,0,0,0,1,0,0,0,0](第5类)在数字识别里代表数字5
|
那
反向传播
反向传播就是把前向传播倒着来一遍更新参数,也就是说,每一层反向传播,我们都要计算三个东西
- dw2:w2的梯度用来更新w2
- db2:b2的梯度用来更新b2
- dA1:传递给前一层的梯度
本质是链式法则,从后往前一层层计算梯度,然后根据每层梯度大小改变权重。
输出层
从输出层开始传播,由之前的前向传播我们知道b3,w3,loss。由定义可知
1
| W3' = W3 - 学习率 × ∂Loss/∂W3(这一块是w3梯度)
|
经过一系列数学化简
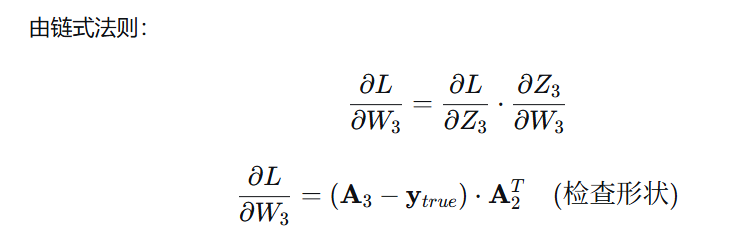
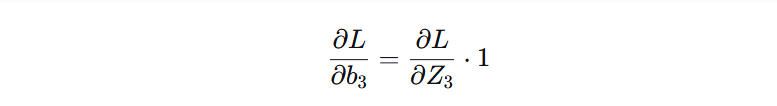
但这里有形状问题:dZ3 是 [batch, 10],而 db3 应该是 [10]。
所以必须把 batch 维度消掉,最简单的方法就是求和(或平均)。
1
2
3
4
5
6
7
8
| dZ3 = [
[0.01, 0.02, -0.10],
[0.03, 0.01, -0.05]
]
sum_dZ3 = [0.01+0.03=0.04, 0.02+0.01=0.03, -0.10-0.05=-0.15]
db3 = [0.02, 0.015, -0.075]
|
所以我们写出代码,注意字母d代表求导
1
2
| dW3 = (A₂.T @ dZ3) / m
db3 = np.sum(dZ3, axis=0, keepdims=True) / m
|
/m 是因为我们计算的是平均梯度,而不是总梯度。损失函数是平均值。
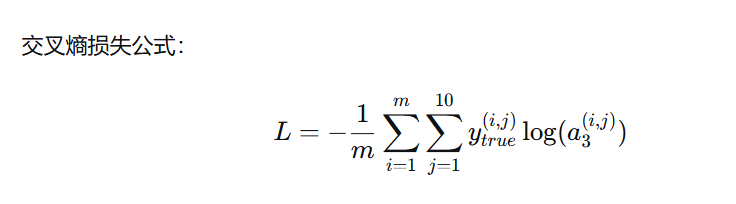
后续层
以下的都是数学推导,由链式法则求导得出,转置则是因为维度不匹配
1
2
3
4
5
| dA2 = dZ3 @ self.params['W3'].T
dZ2 = dA2 * (z2 > 0).astype(float)
dW2 = (a1.T @ dZ2) / m
db2 = np.sum(dZ2, axis=0, keepdims=True) / m
|
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
| import numpy as np
import gzip
import torchvision
import os
from sklearn.preprocessing import LabelBinarizer
np.random.seed(42)
class FFN:
def __init__(self, layer_sizes):
self.params = {}
for i in range(1, len(layer_sizes)):
in_dim = layer_sizes[i-1]
out_dim = layer_sizes[i]
self.params[f'W{i}'] = np.random.randn(in_dim, out_dim) * np.sqrt(2.0 / in_dim)
self.params[f'b{i}'] = np.zeros((1, out_dim))
def forward(self, X):
z1 = X @ self.params['W1'] + self.params['b1']
a1 = np.maximum(0, z1)
z2 = a1 @ self.params['W2'] + self.params['b2']
a2 = np.maximum(0, z2)
z3 = a2 @ self.params['W3'] + self.params['b3']
exp = np.exp(z3 - np.max(z3, axis=1, keepdims=True))
a3 = exp / np.sum(exp, axis=1, keepdims=True)
cache = {
'X': X,
'z1': z1, 'a1': a1,
'z2': z2, 'a2': a2,
'z3': z3, 'a3': a3
}
return a3, cache
def backward(self, y_true, cache):
m = y_true.shape[0]
gradients = {}
X = cache['X']
a1 = cache['a1']
a2 = cache['a2']
a3 = cache['a3']
z1 = cache['z1']
z2 = cache['z2']
dz3 = a3 - y_true
dW3 = a2.T @ dz3 / m
db3 = np.sum(dz3, axis=0, keepdims=True) / m
dA2 = dz3 @ self.params['W3'].T
dz2 = dA2 * (z2 > 0).astype(float)
dW2 = (a1.T @ dz2) / m
db2 = np.sum(dz2, axis=0, keepdims=True) / m
dA1 = dz2 @ self.params['W2'].T
dz1 = dA1 * (z1 > 0).astype(float)
dW1 = (X.T @ dz1) / m
db1 = np.sum(dz1, axis=0, keepdims=True) / m
gradients['dW3'] = dW3
gradients['db3'] = db3
gradients['dW2'] = dW2
gradients['db2'] = db2
gradients['dW1'] = dW1
gradients['db1'] = db1
return gradients
def update(self, gradients, lr):
self.params['W1'] -= lr * gradients['dW1']
self.params['b1'] -= lr * gradients['db1']
self.params['W2'] -= lr * gradients['dW2']
self.params['b2'] -= lr * gradients['db2']
self.params['W3'] -= lr * gradients['dW3']
self.params['b3'] -= lr * gradients['db3']
def predict(self, X):
a3, _ = self.forward(X)
return np.argmax(a3, axis=1)
def accuracy(self, X, y):
y_pred = self.predict(X)
return np.mean(y_pred == y)
|